Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data 的第四章
目的
查找相似的文件/网站/图片
使用实例:冗余网站、查重等
社交网络分析
网易云音乐推荐、Netflix个性化推荐
差异分析
两个文本之间的相似度衡量
- Hamming Distance (汉明距离)
- Distance Functions(距离函数)
- Jaccard similarity 相似性系数
Hamming Distance 汉明距离
在信息理论中,Hamming Distance 表示两个等长字符串在对应位置上不同字符的数目,我们以 d(x, y) 表示字符串x和y之间的汉明距离。从另外一个方面看,汉明距离度量了通过替换字符的方式将字符串 x 变成 y 所需要的最小的替换次数。
1 | // 举例说明以下字符串间的汉明距离为: |
Euclidean Distance 欧几里得度量(欧式距离)
欧氏距离是指在 m 维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。m 维空间中两个点之间的真实距离(不管是一维还是二维、三维,都是代表着真实的距离)。
两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离为
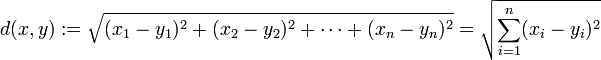
在二维空间中欧氏距离计算公式为:
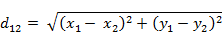
示例:
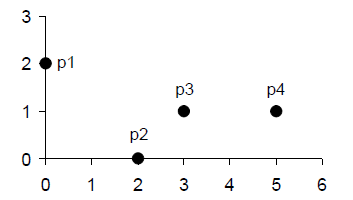
上图中各点的坐标为:
p1 = (0, 2)
p2 = (2, 0)
p3 = (3, 1)
p4 = (5, 1)
各点间欧氏距离为:
| P1 | P2 | P3 | P4 | |
|---|---|---|---|---|
| P1 | 0 | 2.828 | 3.162 | 5.099 |
| P2 | 2.828 | 0 | 1.414 | 3.162 |
| P3 | 3.162 | 1.414 | 0 | 2 |
| P4 | 5.099 | 3.162 | 2 | 0 |
Manhattan Distance 曼哈顿距离
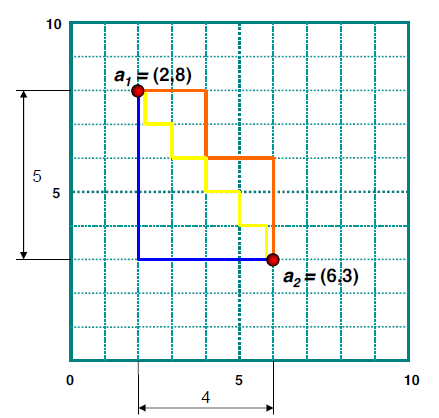
我们可以定义曼哈顿距离的正式意义为 L1 - 距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1,y1)的点 P1 与坐标(x2, y2)的点 P2 的曼哈顿距离为:|x1-x2|+|y1-y2|,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离为
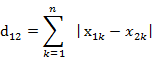
在二维空间中曼哈顿距离计算公式为:
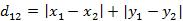
示例:

a1 = (2, 8)
a2 = (6, 3)
dist = |2-6| + |8-3| = 4+5 = 9
距离度量函数
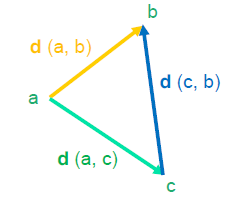
一个函数 d 是距离度量函数需要具备以下条件
- 非负,d(a, b) >= 0
- 恒等,if (a==b) d(a, b) = 0
- 对称,d(a, b) = d(b, a)
- 三角不等式,d(a, b) <= d(a, c) + d(c, b)
1. 聚类概述
聚类:使用无监督学习对类似对象进行分组
监督学习:使用带有标签的物体
无监督学习:使用不带标签的物体
聚类查找数据中的隐藏结构,基于属性的相似性,通常用于探索性分析且没有预测
什么是聚类
针对一组数据对象做处理,使得组内的对象彼此相似(或相关)并且与其他组中的对象不同(或不相关),即组内距离最小化、组间距离最大化
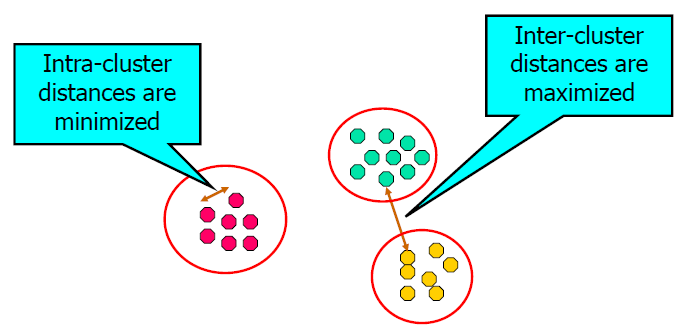
对对象(受访者,产品,公司,变量等)进行分组,以便每个对象与类中的其他对象类似,并且与所有其他类中的对象不同。
示例:
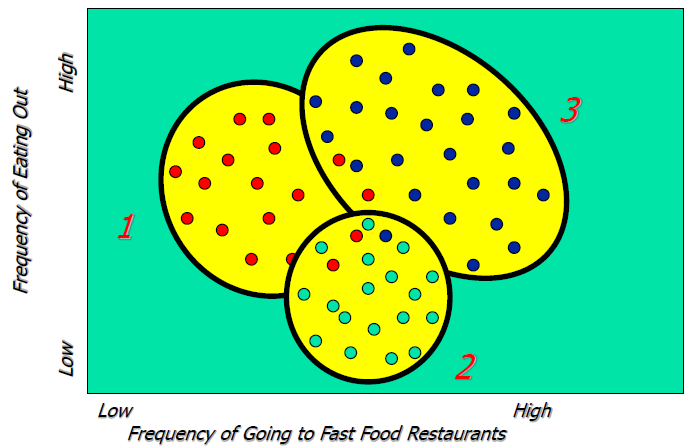
我们可以用聚类干什么
- 确定集群的含义
- 解释如何使用集群
聚类设计注意事项:
- 异常值检测
- 相似度/距离测量
三个基本的问题:
如何衡量相似度?
距离算法
如何形成集群?
层次聚类(Hierarchical Clustering)、K-means算法等
有多少个集群?
- 验证聚类,检查连个、三个、四个甚至更多集群的聚类解决方案
- 根据 “先验” 标准、实际判断、常识、理论基础和统计意义选择集群数
概念步骤:
- 确定要聚类的变量
- 确定是否存在集群。 需要验证集群在统计上是否不同且理论上有意义(可以分配逻辑名称)
- 初步决定要使用的集群数量
- 使用人口统计学,心理学等描述派生集群的特征
示例:
埃里克和他的朋友们聚会, 他们决定分享他们收藏的葡萄酒。问如何分类这些葡萄酒?

列出葡萄酒的属性,在其中选择聚类特征变量。 在这种情况下,我们选择评级和价格
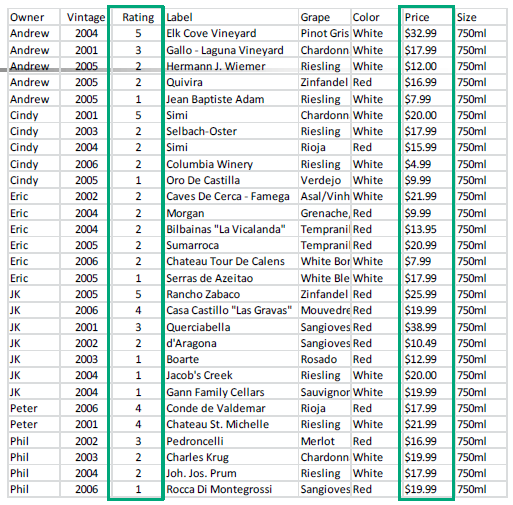
将表转换为散点图
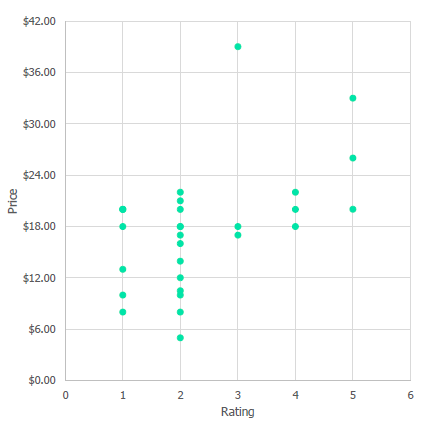
我们可以说有两个集群:低评级和低价格、高评级和高价格
决定使用这两个集群
进行聚类
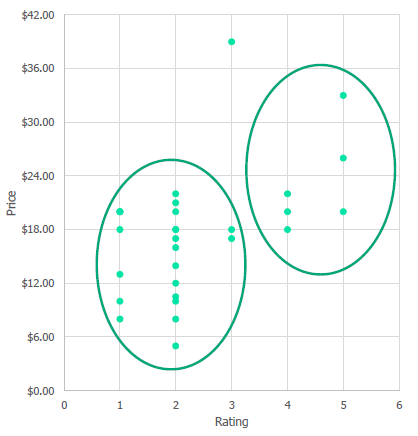
但是有一个异常值
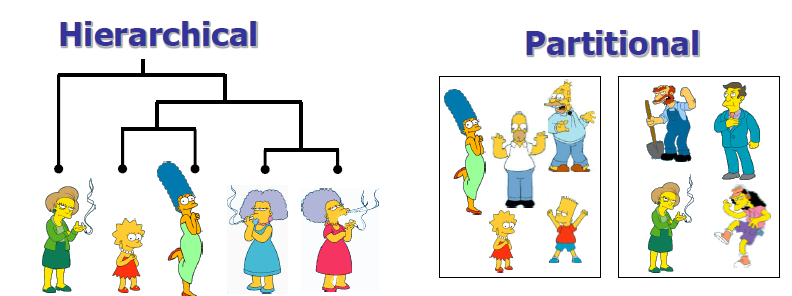
2. 聚类的两种类型
划分聚类(Partitional algorithms):构造各种分区,然后按一些标准评估它们
层次聚类(Hierarchical algorithms):使用某个标准(通常为距离)创建对象集的层次分级
K-means(基于划分的聚类 Partitional algorithms)
给定一组具有 n 个可测量属性的对象的数据集和集群的划分数量 k,该算法根据每个对象到这 k 个组的中心的邻近长度区分这 k 个组
采用迭代的重定位技术,尝试通过对象在划分间移动来改进划分。所谓重定位技术,就是当有新的对象加入簇或者已有对象离开簇的时候,重新计算簇的平均值作为中心(簇中对象各维向量的平均值),然后对对象进行重新分配。这个过程不断重复,直到各簇中对象不再变化为止。
使用示例:
聚类通常被应用于以属性作为标识的集群的分类
- 图像处理:对于安全图像,检查连续帧以区分修改
- 医疗:可以将患者按照先天因素分组
- 客户划分:销售团队区分具有相似行为和消费模式的客户
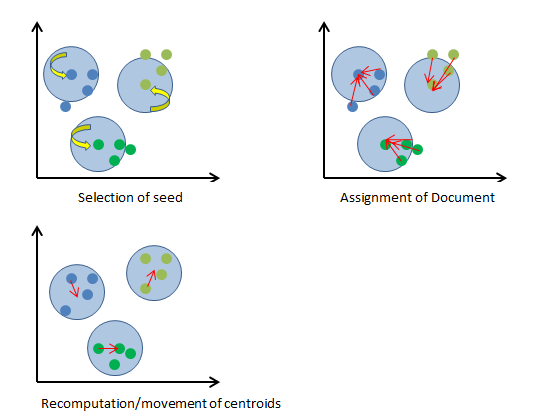
K-means的步骤概述:
- 选择 k 的值和聚类中心的初始猜测值
- 计算从每个数据点到每个聚类中心的距离,并将每个点分配给最近的类
- 从步骤2计算每个新定义的集群的聚类中心
- 重复步骤2和3,直到算法收敛(不发生更改)
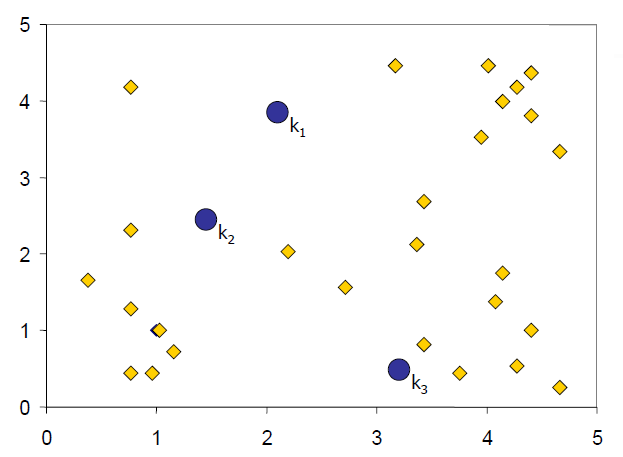
示例1:
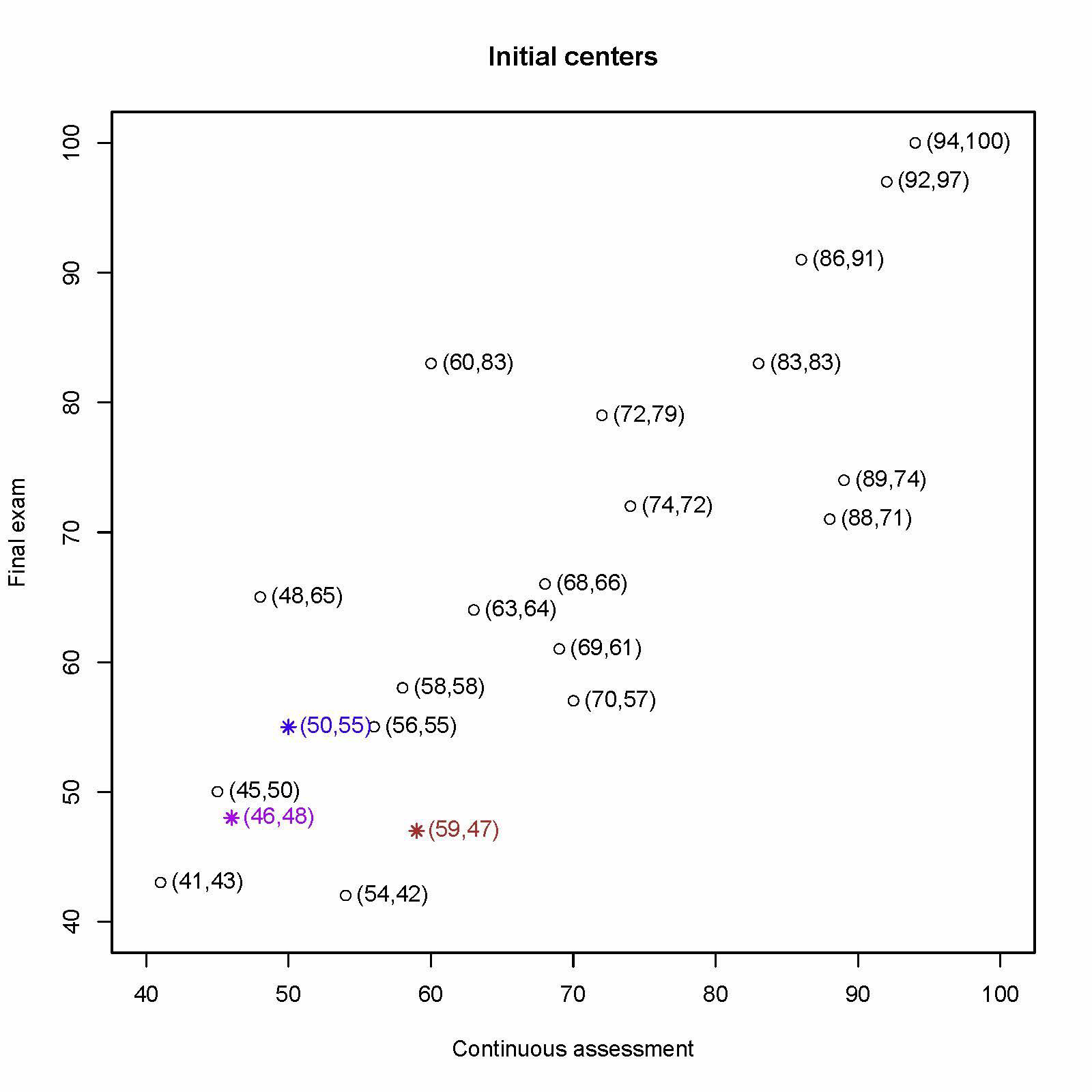
设置 k = 3 和初始聚类中心
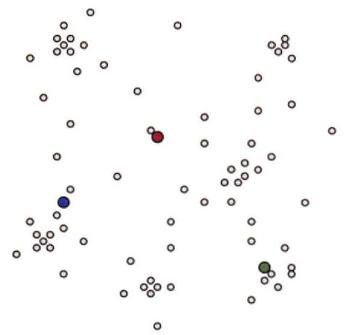
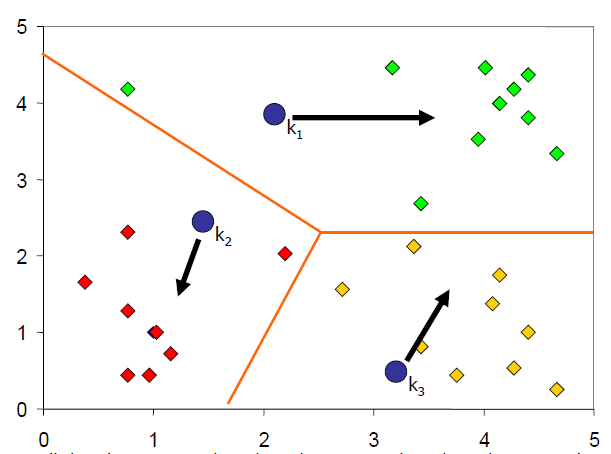
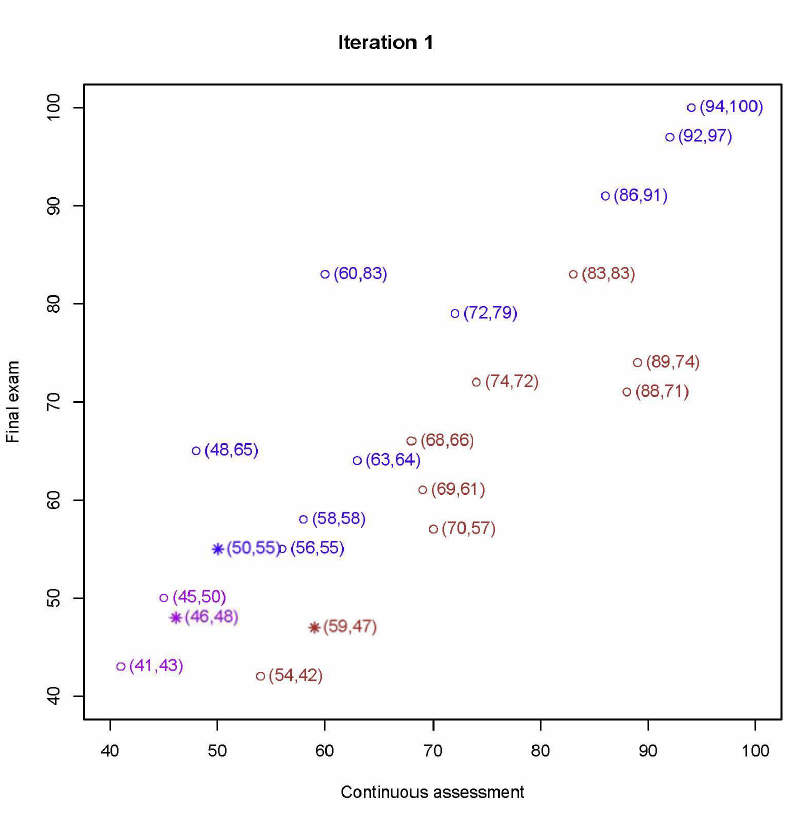
点被分配给最近的类(根据点到聚类中心的距离分配)
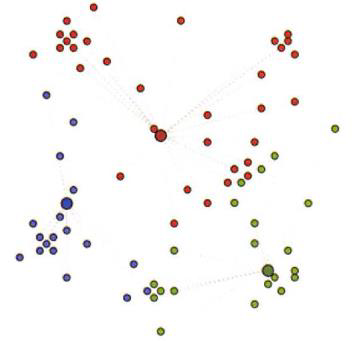
计算新集群的聚类中心
重复第2、3步直到收敛
当聚类中心不改变或聚类中心来回振荡时收敛(当一个或多个点与聚类中心距离相等时,可能会发生这种情况)
基本的 K-means 算法:
选择要确定的 K 个集群
随机选择 K 个对象作为初始聚类中心
重复 3
- 将每个对象分配给最近的集群
- 计算每个集群新的聚类中心
直到
集群中心没有变化(即聚类中心不再改变位置)
或者
没有对象更改其集群(我们也可以定义停止条件)
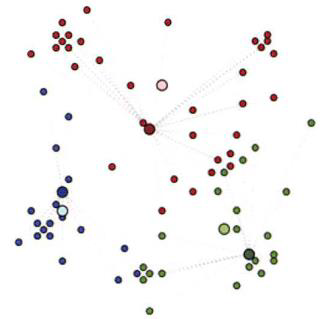
示例2:
算法:K-means
距离度量:Euclidean Distance 欧几里得度量(欧式距离)
确定集群的数量并随机设置相同数量的 k 个节点(聚类中心)
根据它们到 k 个节点的距离对所有对象进行聚类。 然后重新设置第1步产生的 k 个节点(聚类中心)
根据每个对象到k个节点的距离重新聚类
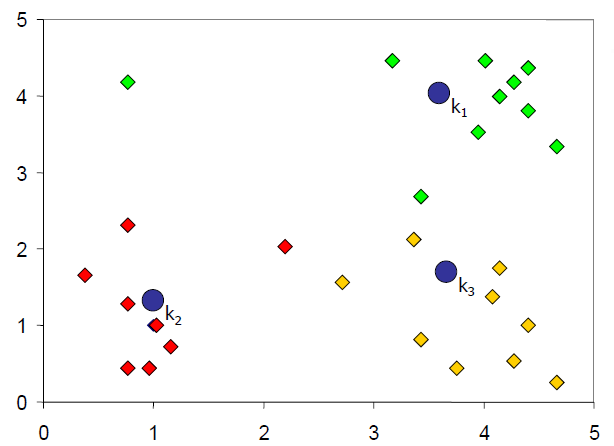
重新设置 k 个节点(聚类中心),即将k个节点移动到其集群的中心
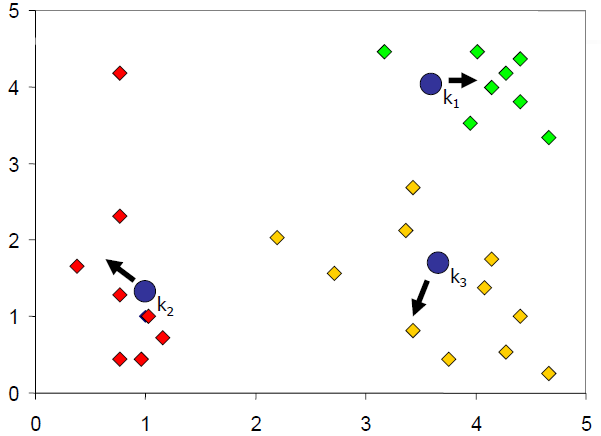
重复步骤3和4,直到 k 个节点不改变位置
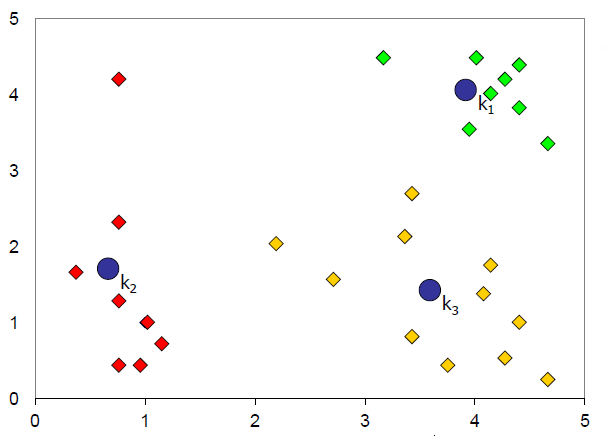
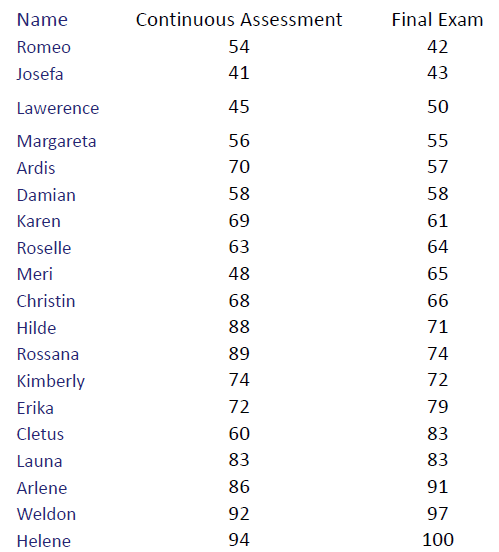
示例3:
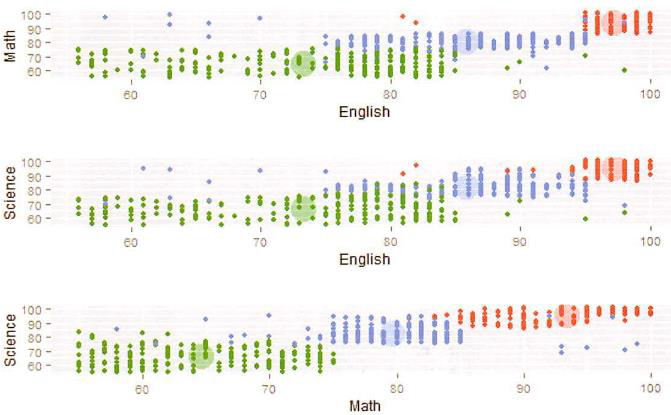
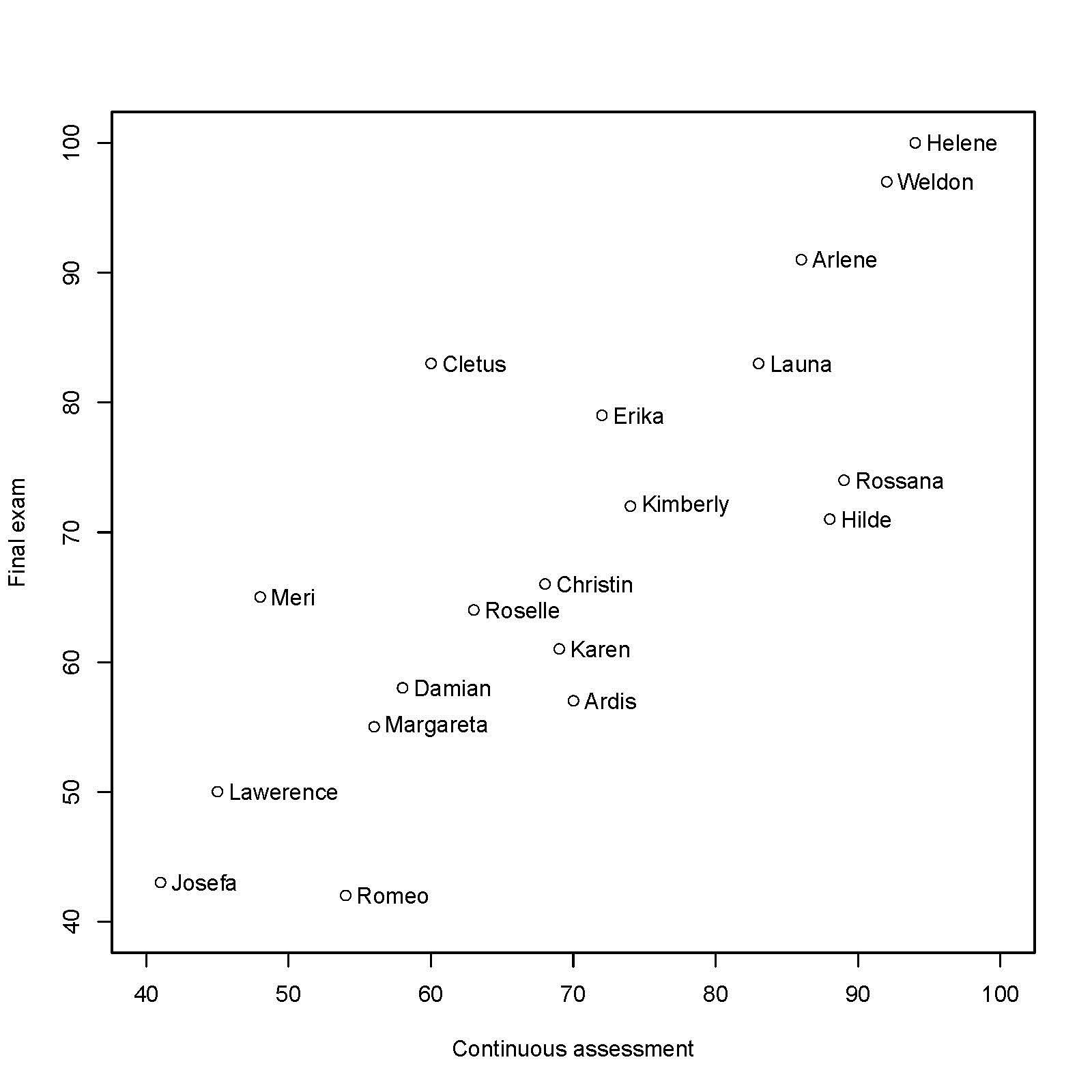
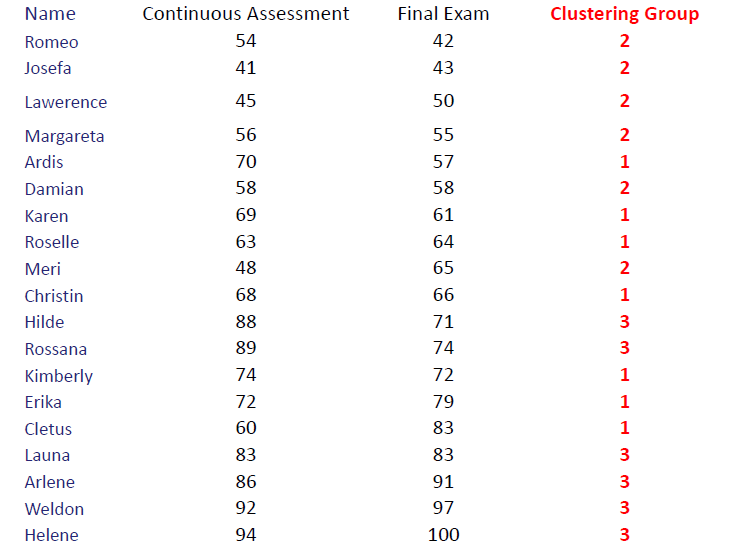
现有学生成绩如下图:
绘制散点图如下:
初始化三个中心:
将每个学生分配到最近的中心:
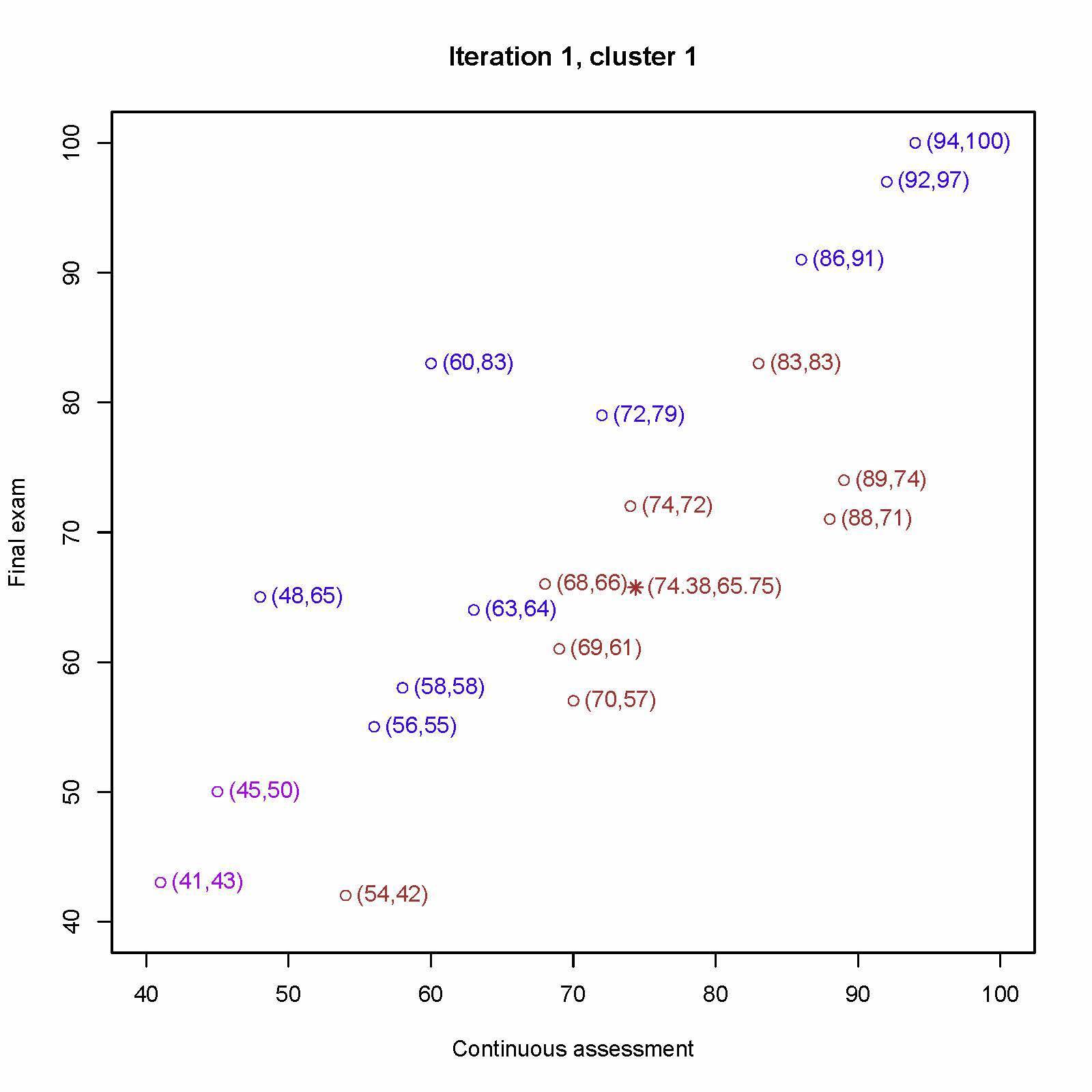
重新计算第一个中心 (54, 42)、(70, 57)、(69, 61)、(68, 66)、(88, 71)、(89, 74)、(74, 72)、(83, 83) 的平均值为 (74.38, 65.75)
重新计算第二个中心 (41, 43)、(45, 50) 的平均值为 (43.00, 46.50)
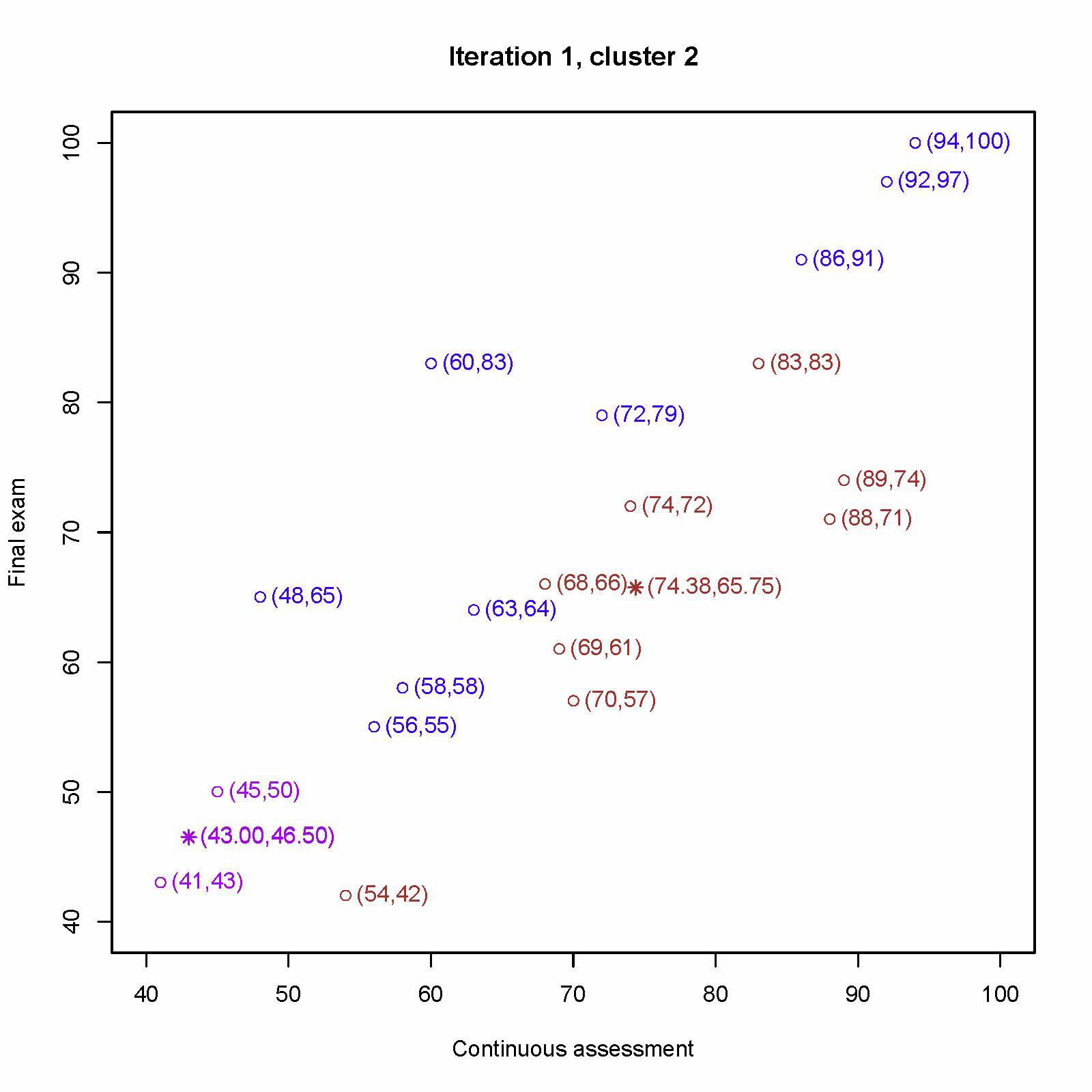
重新计算第三个中心 (56, 55)、(58, 58)、(63, 64)、(48, 65)、(72, 79)、(60, 83)、(86, 91)、(92, 97)、 (94, 100) 的平均值为 (69.89, 76.89)
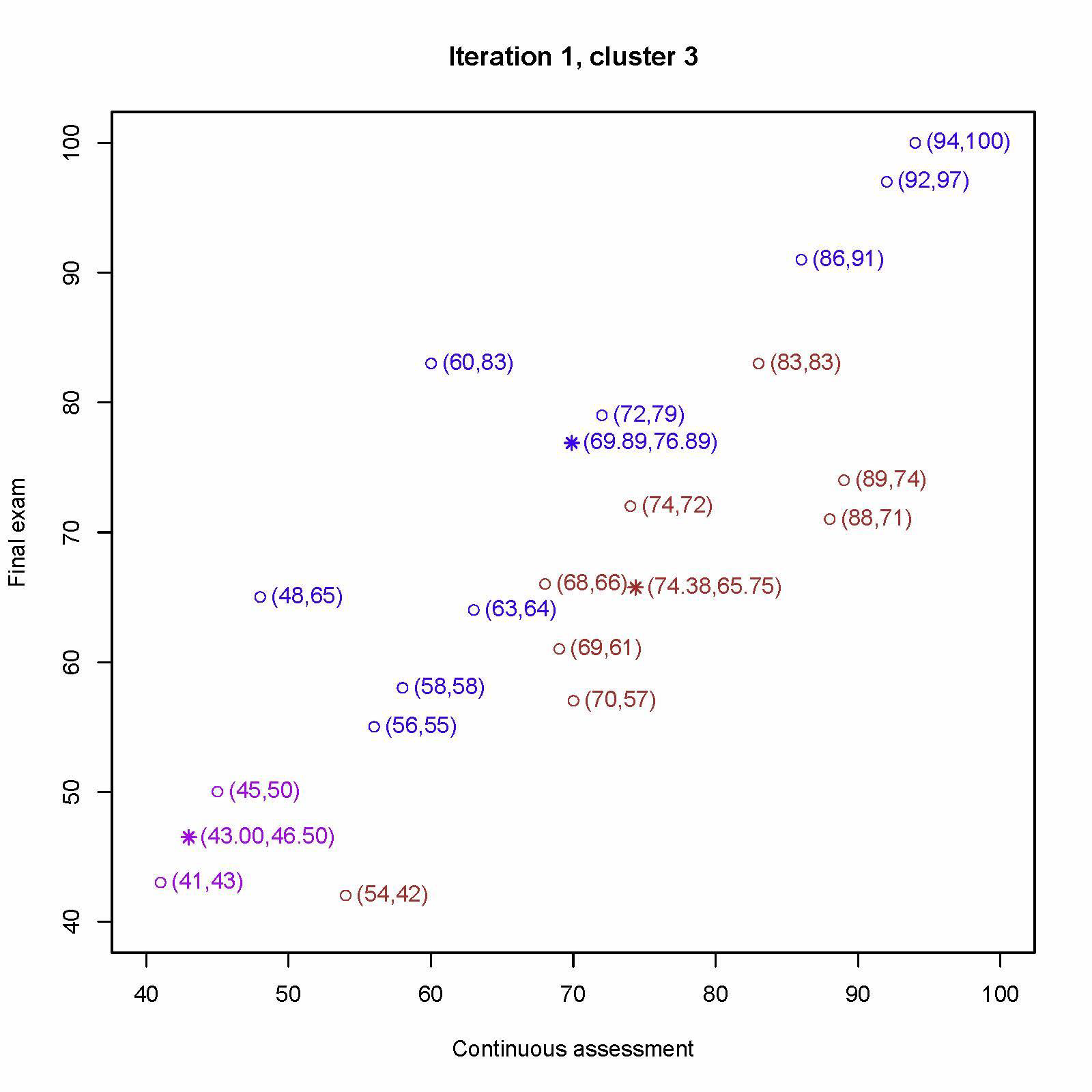
重新分配每个学生最近的中心
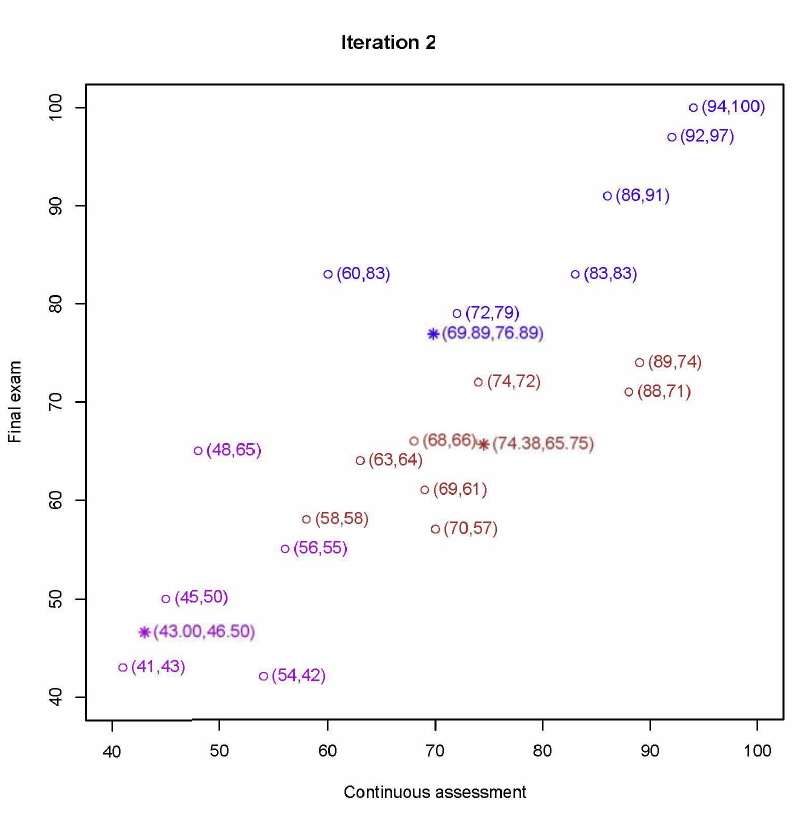
重新计算第一个中心 (70, 57)、(58, 58)、(69, 61)、(63, 64)、(68, 66)、(88, 71)、(89, 74)、(74, 72) 的平均值为 (72.38, 65.38)
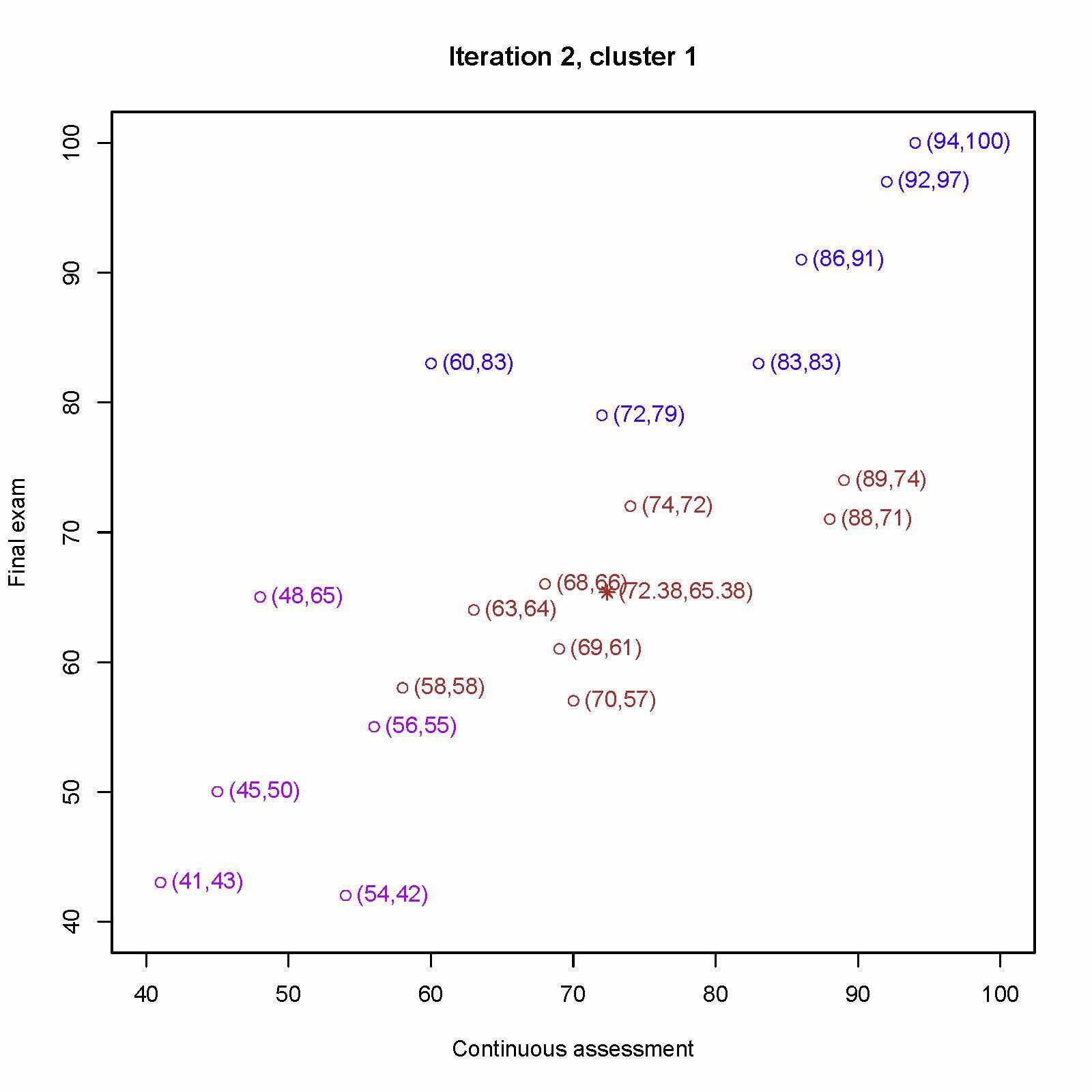
重新计算第二个中心 (54, 42)、 (41, 43)、(45, 50) 、(56, 55)、(48, 65) 的平均值为 (48.80, 51.00)
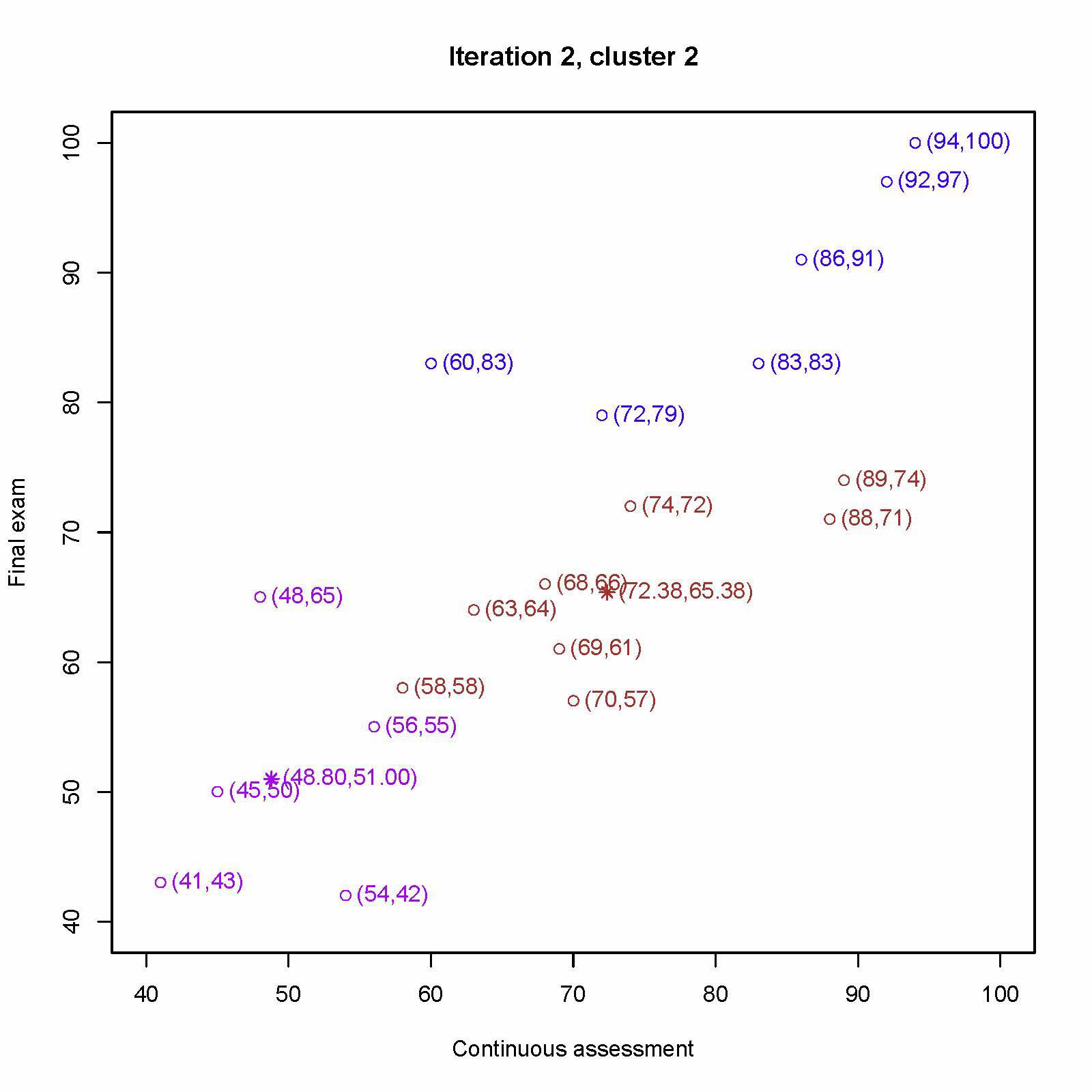
重新计算第三个中心 (72, 79)、(60, 83)、(83, 83)、(86, 91)、(92, 97)、 (94, 100) 的平均值为 (81.17, 88.83)
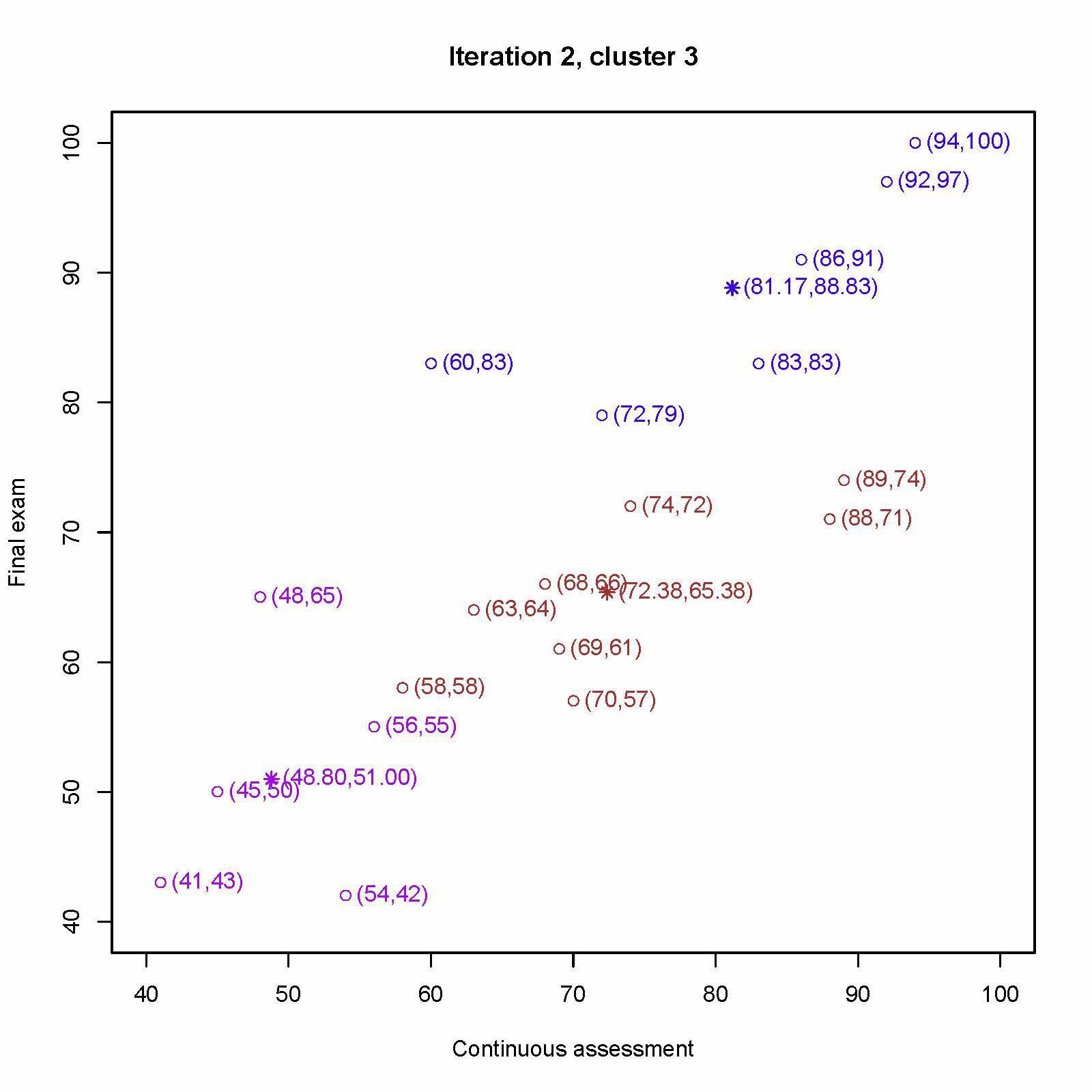
重新分配每个学生最近的中心,重新计算第一个中心 (70, 57)、(69, 61)、(63, 64)、(68, 66)、(88, 71)、(74, 72)、(60, 83) 的平均值为 (70.29, 67.71)
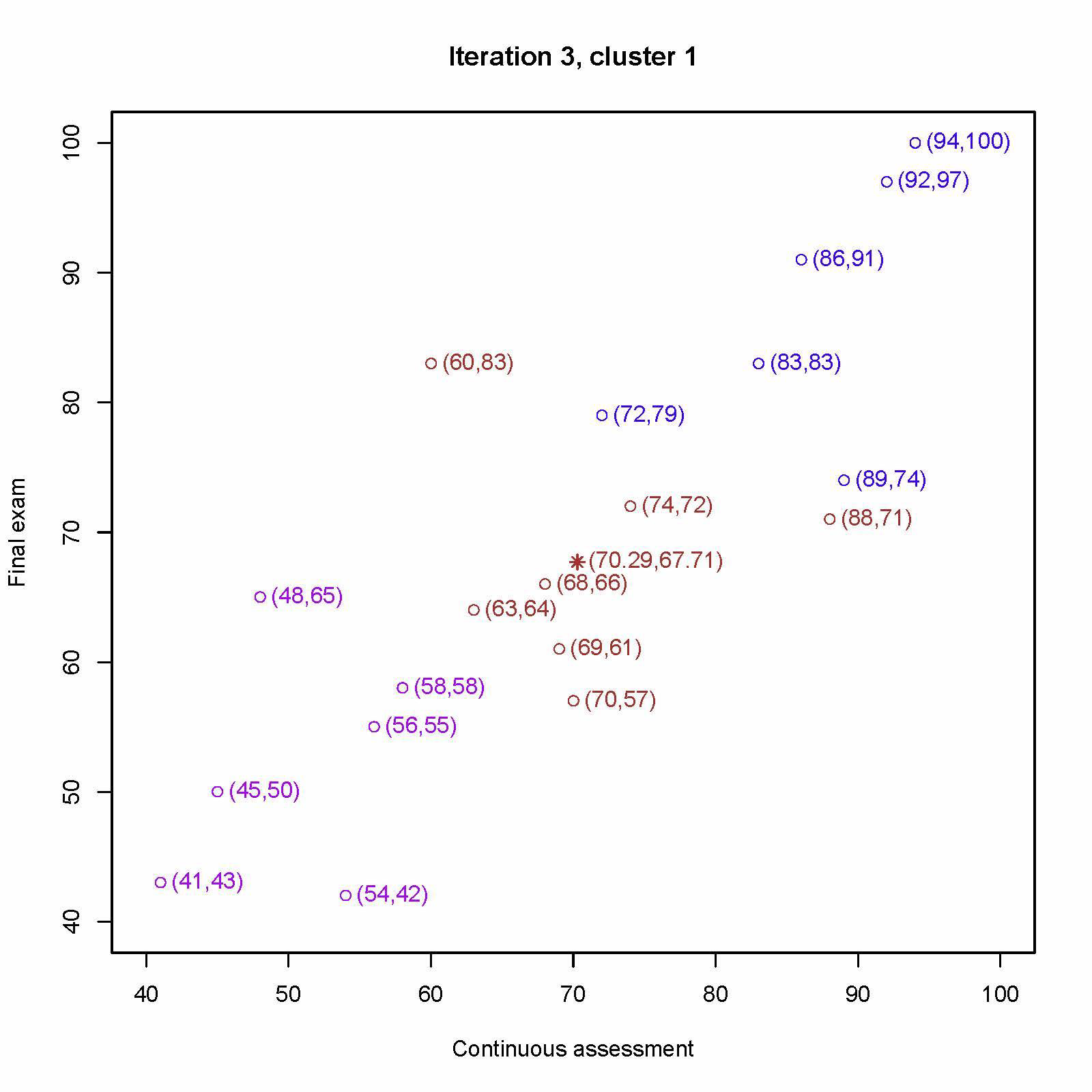
重新计算第二个中心 (54, 42)、 (41, 43)、(45, 50) 、(56, 55)、(58, 58)、(48, 65) 的平均值为 (50.33, 52.17)
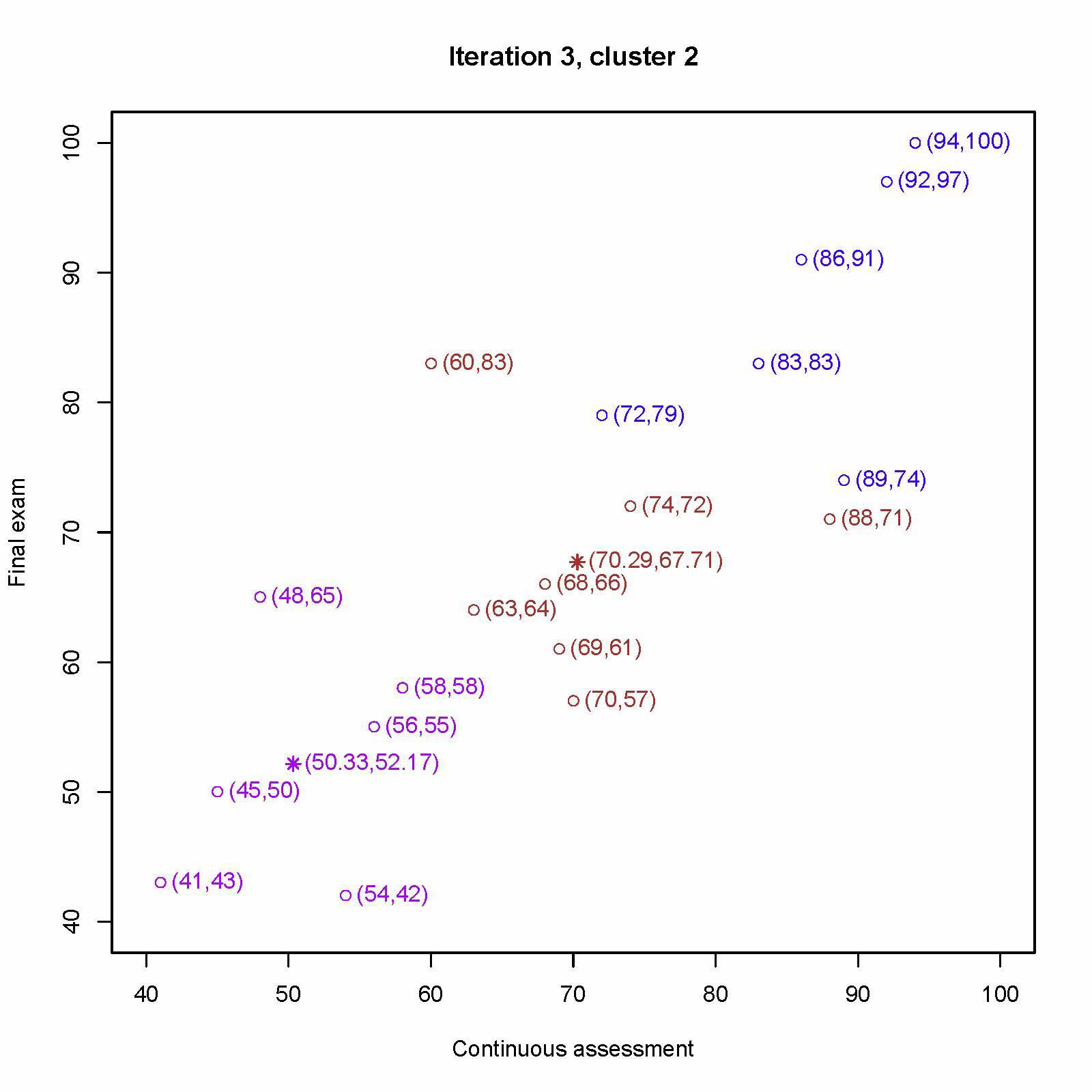
重新计算第三个中心 (89, 74)、(72, 79)、(83, 83)、(86, 91)、(92, 97)、 (94, 100) 的平均值为 (86.00, 87.33)
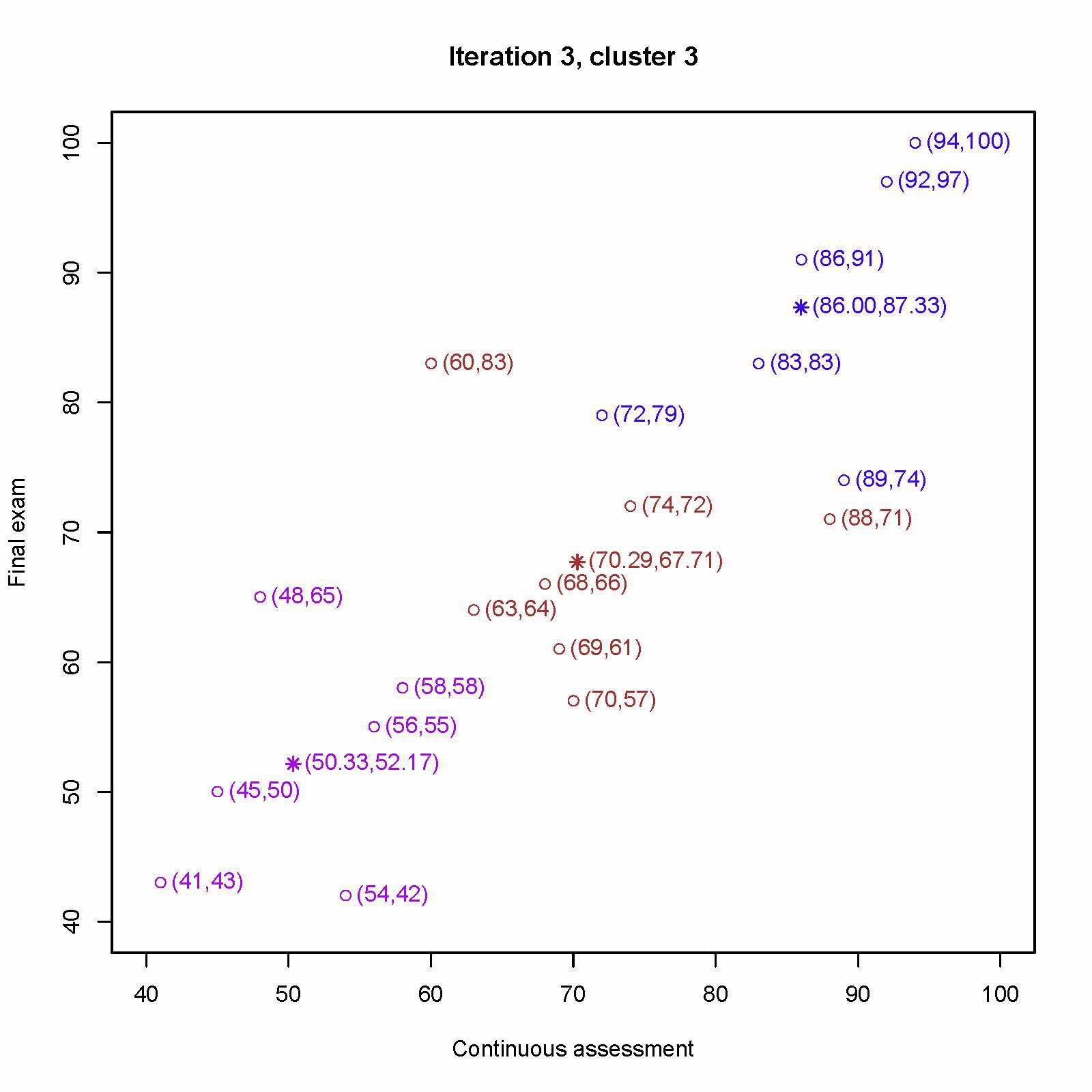
重新分配每个学生最近的中心,重新计算第一个中心为 (68.00, 68.86)、第二个中心为 (50.33, 52.17)、第三个中心为 (88.67, 86.00)
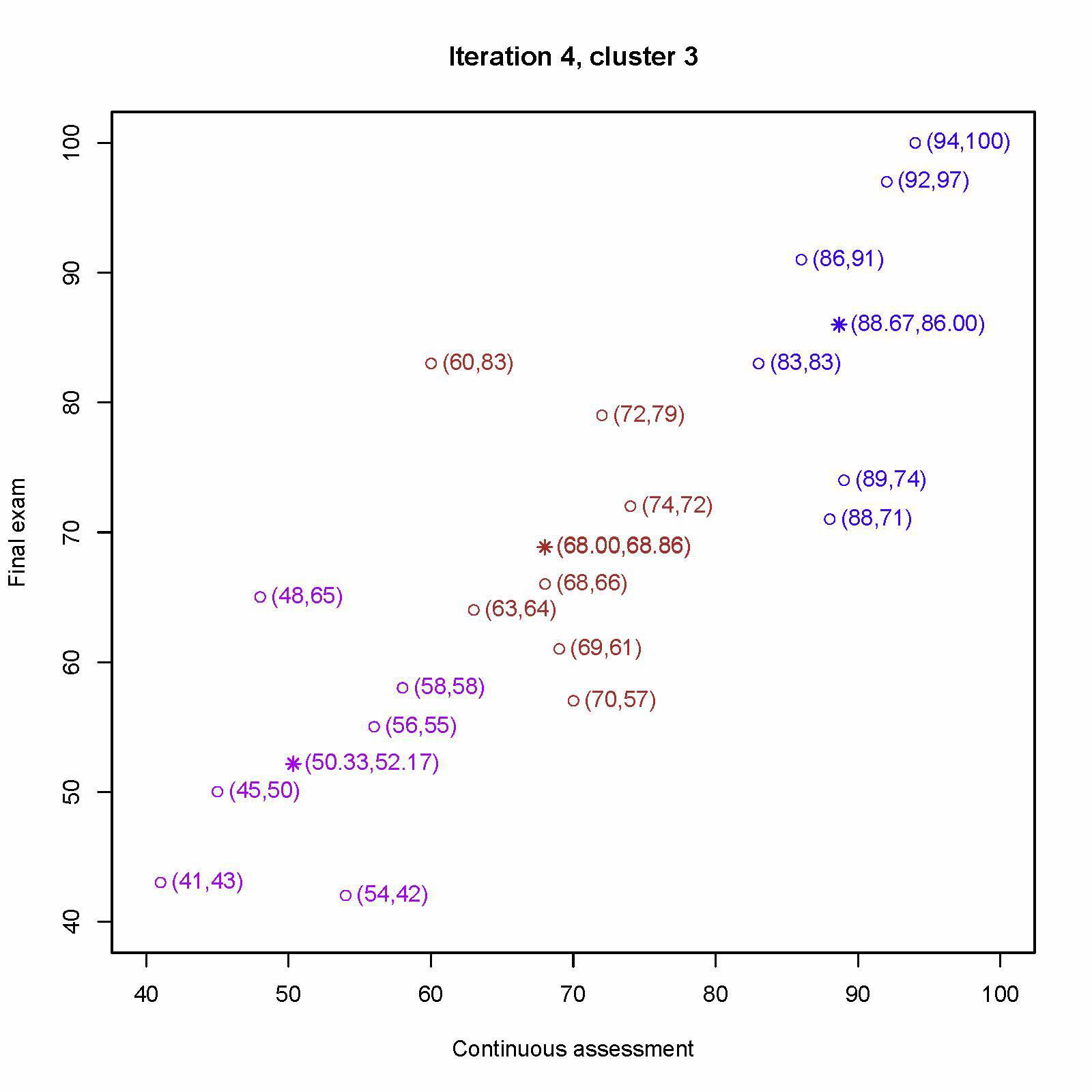
最终分组为:
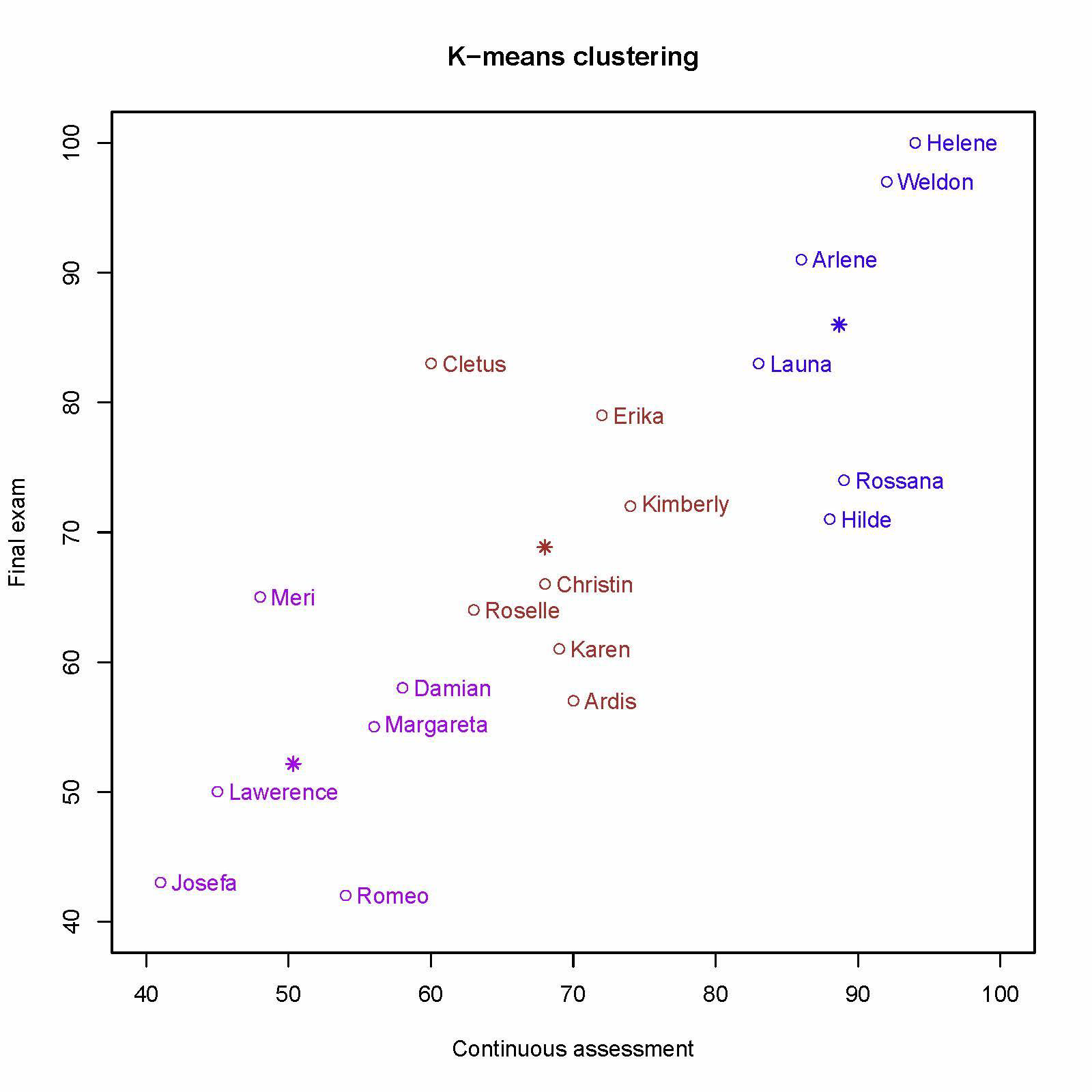
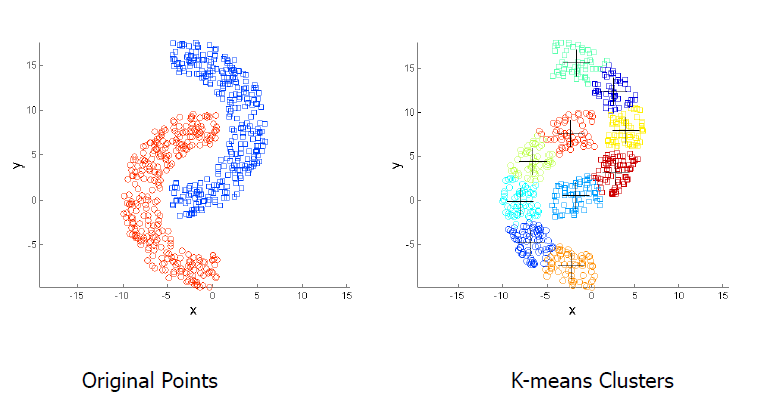
K-means 的局限性:非球形体
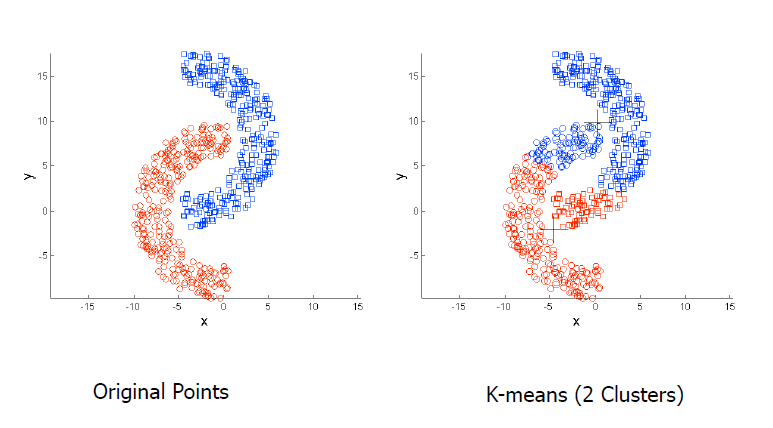
解决:
优缺点分析:
优点:
- 相对有效
- 通常终止于
局部最优。 只能找到固定数量的簇的最佳解决方案。 无法找到所有可能解决方案中的最佳解决方案。 在确定性退火技术(deterministic annealing)和遗传算法(genetic algorithms)和可能找到全局最优解
缺点:
- 仅在定义平均值时适用,那么分类数据呢?
- 需要事先指定 k,集群的数量
- 无法处理乱的数据和异常值
- 不适合发现具有
非凸形状的集群
Hierarchical Clustering(层次聚类)
层次结构通常用于组织信息,例如在门户网站中
示例1:雅虎

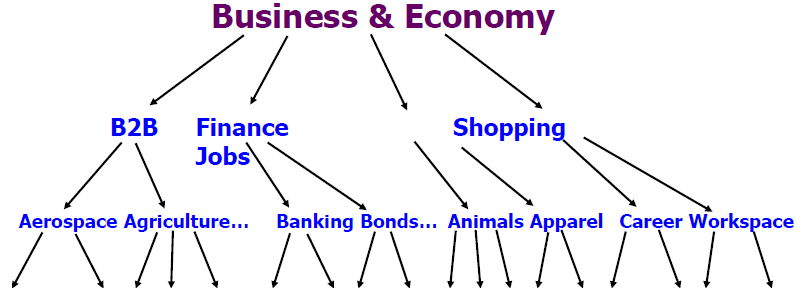
雅虎的层次结构是手动创建的,我们将专注于自动创建数据挖掘中的层次结构。
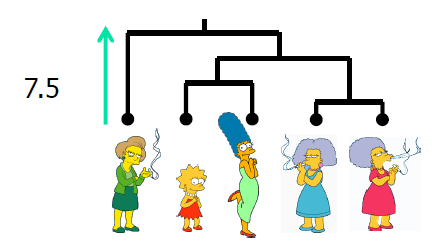
用于总结相似性度量的有用工具——树形图
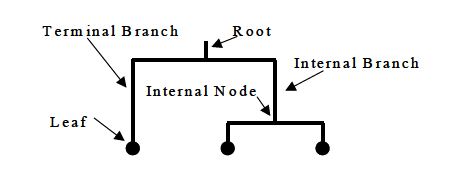
树形图中两个对象之间的相似性表示为它们共享的最低内部节点的高度。
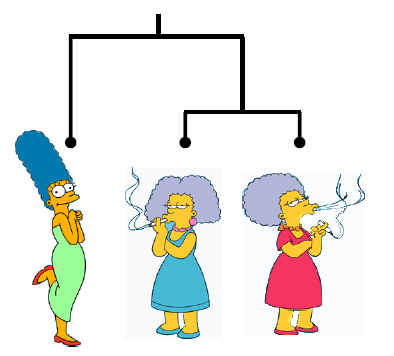
我们可以查看树形图以确定“正确”的簇数。 在这种情况下,两个高度分离的子树高度暗示了两个簇。 (很少出现这种情况)
示例2:
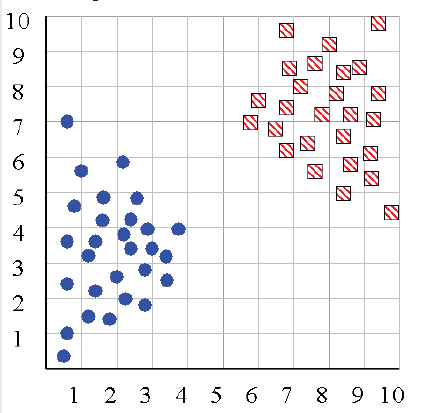

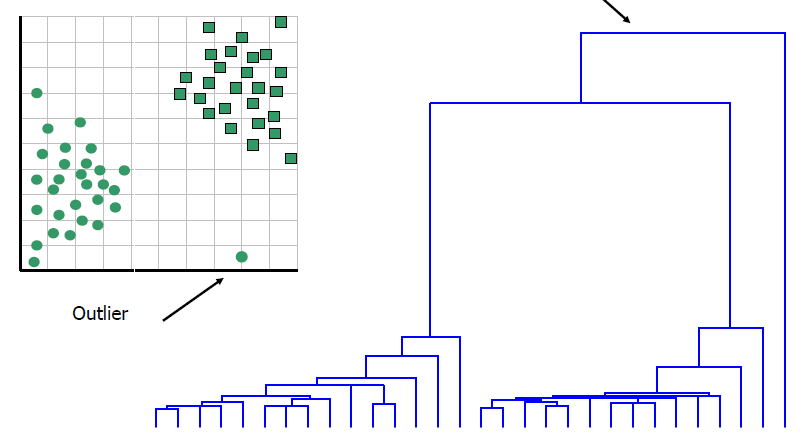
树形图的一个潜在用途是检测异常值 ,单个独立的分支暗示了与所有其他分支非常不同的数据点
示例3:
单连接算法(Single-Linkage)
我们从距离矩阵开始,该矩阵包含数据库中每对对象之间的距离。
示例4:
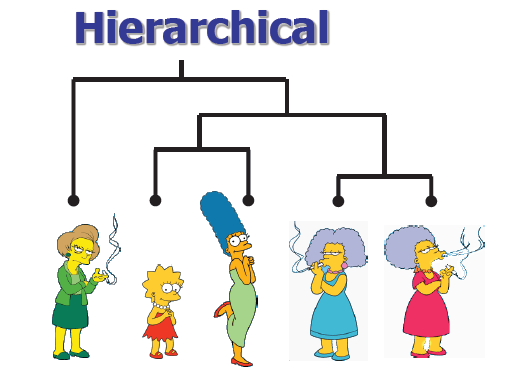
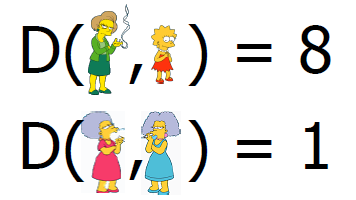
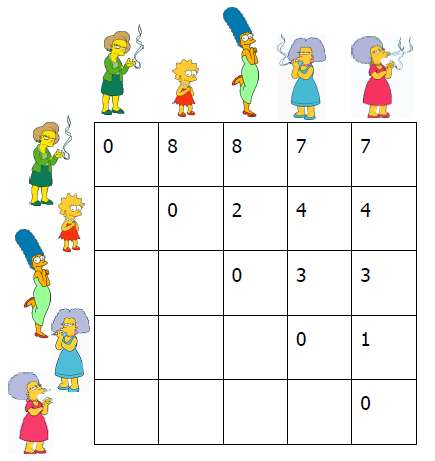
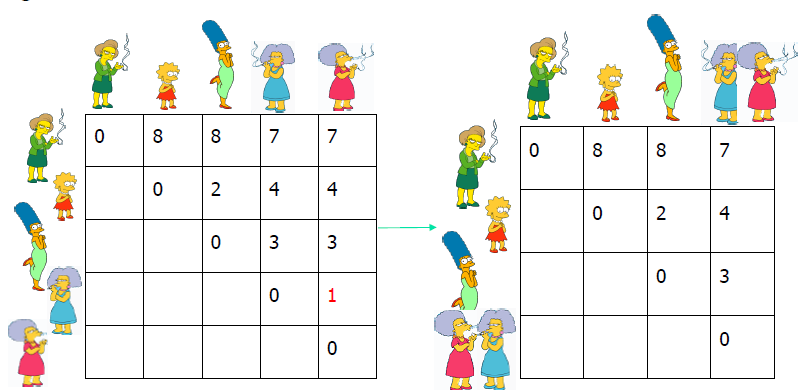
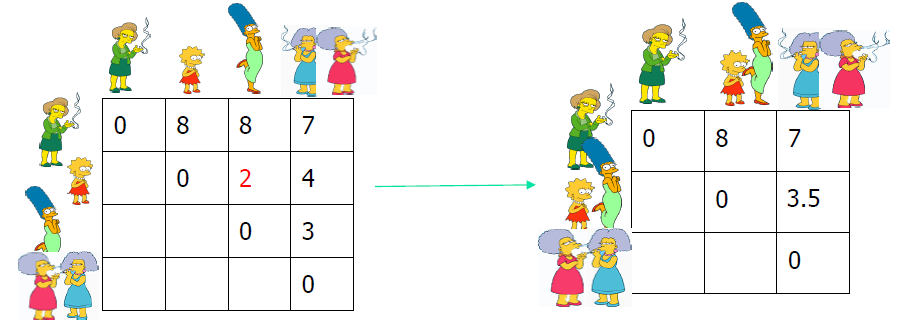
自下而上(凝聚):从其自己的集群中的每个项目开始,找到要合并到新集群中的最佳对。 重复,直到所有集群都融合在一起。
什么是好的聚类算法
- 一个好的聚类算法将产生具有组内相似度高、组间相似度低的集群
- 准确定义聚类算法的质量很困难,通常是依赖应用的并且是主观的
为什么要使用聚类
- 它的主要任务是
探索性数据挖掘,也是统计数据分析的常用技术,可以应用于许多领域以及现实生活中 - 实际上,聚类是最常用的数据挖掘技术之一。它历史悠久,几乎用于各个领域,如工程,科学,医学,心理学,植物学,社会学,生物学,考古学,市场营销,保险,图书馆等
举例
为不同高度、不同体重的人制作大中小型号的衣服(XS、S、M、L、XL、XXL 等)
为所有人定制太贵,一刀切又不适合所有人
在营销中,根据客户的相似性对客户进行细分。做针对性的营销
给定一组文本文档,我们希望根据它们的内容相似性来组织它们,生成主题层次结构(书店中书的排列)
实际应用
- 便于理解:相关文档及参考文献,具有相似功能的基因组和蛋白质,或具有相似价格波动的股票组
- 概要展示:减小大数据集的大小。天气预报中的气温图、降雨图
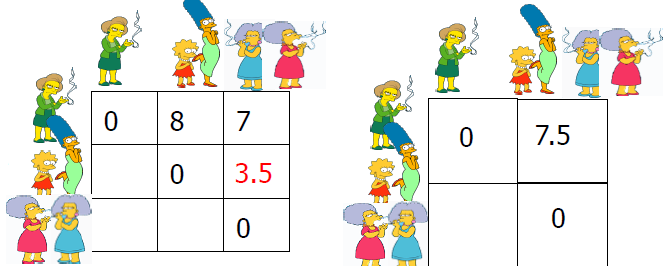
例1:人群(物体)的划分

辛普森一家和学校的员工

男和女

例2:
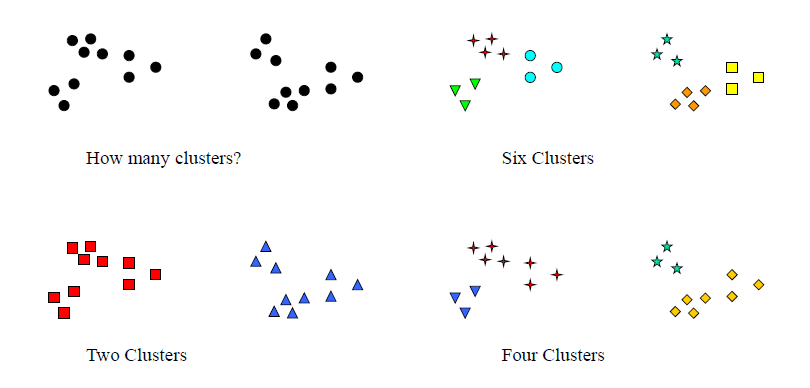
3. 如何确定集群的最佳数量
合理的猜测
预定义的要求
使用启发式方法 - 例如,内部平方和(WSS)
WSS度量是每个数据点与最近聚类中心之间的距离的平方和
识别 k 的适当值的过程被称为找到 WSS 曲线的拐点(WSS为纵坐标,集群数量为横坐标)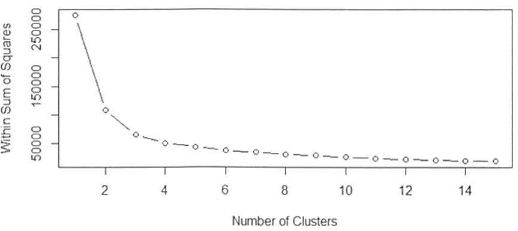
曲线的拐点发生在 K = 3 的时候
检验
- 当集群的数量很小时,绘制数据有助于改进 k 的选择
- 需要注意
- 集群是否完全分离?
- 所有集群中都只有少量的对象?
- 所有集群的聚类中心是不是太接近了?
选择理由和注意事项
需要做决定
- 分析中应该包含对象的哪些属性?
- 每个属性应该使用哪种度量单位?
- 属性是否需要重新调整?
- 可能还有哪些其他需要考虑的因素?
了解要知道哪些属性才能把新对象分配给集群
客户满意度可用于建模,但不适用于潜在客户
尽可能减少属性数量
- 多属性可以最大限度地减少关键变量的影响
- 找出高度相关的属性
- 将几个属性合并为一个:例如,债务/资产比率
例如:7个属性的散点图矩阵如下:

计量单位
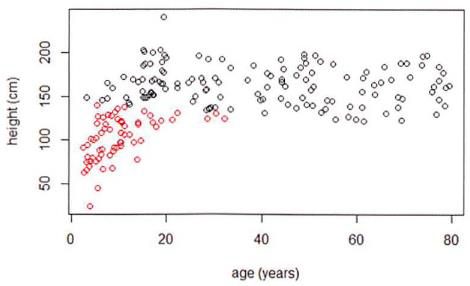
K-means 将根据度量单位识别不同的集群
示例:
身高使用 cm 为单位
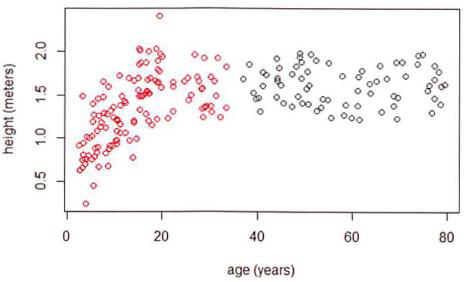
身高使用 m 为单位
重新调整可以减少统治效果
例如,将每个变量除以适当的标准偏差
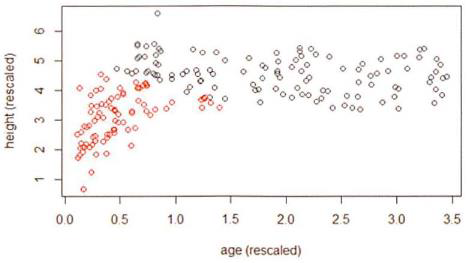
其它考虑因素
K-means对初始聚类中心敏感(替换聚类中心重新运行几次)
可以探索欧氏距离以外的其它度量算法,如汉明距离、曼哈顿距离、马氏距离(Mahalanobis distance)
K-means 适用于数字数据,并且不适用于名词属性,如性别,种族,血型,单词,形状,水果……
4. R语言指令
1 | # K-means 聚类算法 |
5. 总结
- 聚类根据对象的属性对类似对象进行分组
- 要正确聚类,重要的是
- 正确缩放属性值以避免压迫(覆盖)
- 确保指定距离的概念是有意义的
- 仔细选择群集数量
- 识别出集群后,以描述性方式标记集群通常很有用
6. 高中生聚类分析